Publications
-
38- Rustico, L.; Hili, R. "The evolving logic of biocatalyzed nucleic acid synthesis" 2026, submitted.
+Abstract coming soon
-
37- Khamissi, N.; Rustico, L.; Hili, R. “Transcription and reverse transcription of XNA by Ligase-Catalyzed Oligonucleotide Polymerization” Curr Protoc Nucleic Acid Chem, 2026, In Press. Ahead of Print Online.
+The growing utility of xeno-nucleic acids (XNAs) lies in their ability to extend the reach of genetic chemistry beyond the limits imposed by natural polymers. XNAs, with their diverse chemical backbones, resist enzymatic degradation and yet retain the capacity for sequence-defined information, and have found broad applications in biotechnology. The approach described herein provides a systematic method for their transliteration. This protocol delineates the Ligase-Catalyzed Oligonucleotide Polymerization (LOOPER) process as applied to the transcription and reverse transcription of XNA libraries using T3 DNA ligase. Two complementary procedures are presented. Basic Protocol 1 details the assembly of XNA polymers through the ligase-mediated templated ligation of 5′-phosphorylated trinucleotide anticodons bearing XNA modifications, exemplified here by locked nucleic acids (LNAs). Basic Protocol 2 describes the reverse transcription of XNA sequences into cDNA using unmodified DNA 5’-phosphorylated trinucleotide anticodons. Together, these protocols enable a bidirectional exchange between DNA and chemically diverse XNA species, a prerequisite for the application of SELEX and other evolutionary methodologies to noncanonical backbones. This ligase-based framework dispenses with substrate biases that can often be present with polymerases, allowing high-fidelity transliteration (>95%) across a variety of modified nucleotides.
-
36- Khamissi, N.; Rustico, L.; Hili, R. “Generation and Evolution of Diversely Functionalized DNA Libraries Using Ligase-Catalyzed Oligonucleotide Polymerization (LOOPER)” Methods Mol. Biol. 2026, In Press
+Ligase-catalyzed Oligonucleotide Polymerization (LOOPER) enables the synthesis of highly modified nucleic acid libraries, which can be used as pools to evolve functional nucleic acids, such as aptamers. Here we describe the process to generate a LOOPER-derived ssDNA library comprising 16 different chemical modifications installed in a sequence-defined manner. The preparation of the building blocks, their templated polymerization, and strand separation to generate the modified ssDNA library are outlined.
-
35- Khamissi, N.; Korfmann, C.; Chaudhry, A.; Hili, R. "Ligase-catalyzed transcription and reverse-transcription of XNA-containing polymers using T3 DNA ligase" Chem. Sci. 2025, 16, 9749–9755.
+A method to enable the transliteration between various XNA-continaing nucleic acids and canonical DNA is described. Using Ligase-catalysed oligonucleotide polymerisation (LOOPER), we show that DNA can be used as a template to generate nucleic acids polymers comprising various levels of 2’-fluoro (2’-F), 2'-Fluoro-arabinonucleic Acid (FANA), 2’-O-methyl (2’-OMe), and Locked Nucleic Acids (LNA) in moderate yields. The fidelity and biases of the LOOPER process was studied in detail for the 2’-F system by developing a hairpin-based sequecing method, which showed fidelities exceeeding 95% along with positional and sequence dependencies within the polymerised XNA-containing anticondons. Lastly, we show the ability of LOOPER to regenerate DNA from 2’-F, FANA, 2’-OMe, and LNA in moderate yield and in fidelities over 95%. Taken together, this study demonstrates the potential of LOOPER to serve as a platform for applications where the transliteration between XNA and DNA is needed, such as the in vitro evolution of XNA-containing nucleic acid polymers.

-
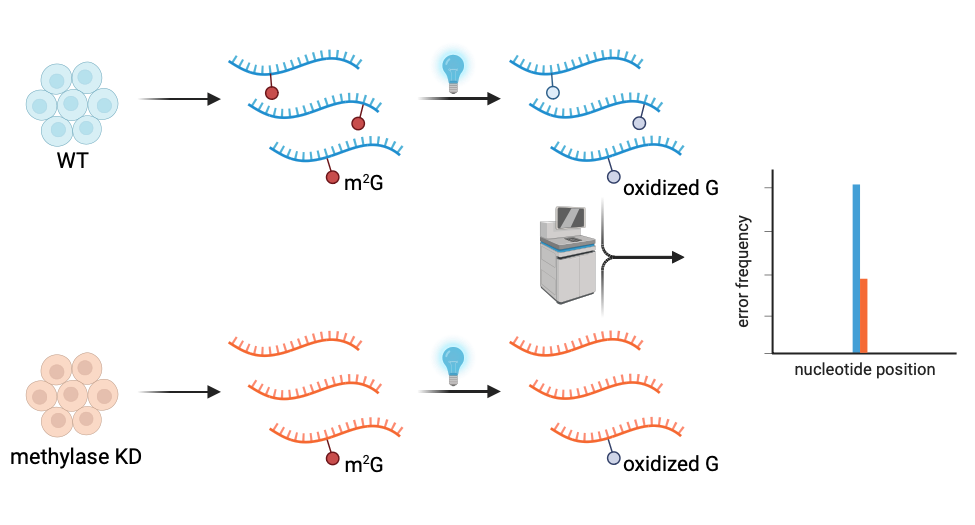
34- Klimontova, M.‡; Chung Kim Chung, K.‡; Zhang, H.‡; Kouzarides, T.; Bannister, A. J.; Hili, R. "PhOxi-seq detects enzyme-dependent m2G in multiple RNA types" ACS Chem. Biol. 2024, 19, 2399–2405.
‡ These authors contributed equally
+ABSTRACT: In recent years, RNA-modifying enzymes have gained significant attention due to their impact on critical RNA-based processes, and consequently human pathology. However, identifying sites of modifications throughout the tran-scriptome remains challenging largely due to the lack of accurate and sensitive detection technologies. Recently, we de-scribed PhOxi-seq as a method capable of confirming known sites of m2G within abundant classes of RNA, namely purified rRNA and purified tRNA. Here, we further explore the selectivity of PhOxi-seq and describe an optimised PhOxi-seq work-flow, coupled to a novel bioinformatic pipeline, that is capable of detecting enzyme-dependent m2G sites throughout the transcriptome, including low abundant mRNAs. In this way, we generated the first database of high confidence sites of THUMPD3-dependent m2G in multiple RNA classes within a human cancer cell line and further identify non-THUMPD3 controlled sites throughout the transcriptome.
>Original preprint of this manuscript is available at BioRxiv
-
33- Klimontova, M.; Zhang, H.; Campos-Laborie, F.; Webster, N.; Andrews, Chung Kim Chung, K.; Hili, R.; Kouzarides, T.; Bannister, A. J. "THUMPD3 regulates alternative splicing of ECM transcripts in human lung cancer cells and promotes proliferation and migration" Plos One 2024, 19(12): e0314655. https://doi.org/10.1371/journal.pone.0314655
+RNA-modifying enzymes have recently garnered considerable attention due to their relevance in cancer biology, identifying them as potential targets for novel therapeutic intervention. THUMPD3 was recently identified as an RNA methyltransferase catalysing N2-methylguanosine (m2G) within certain tRNAs. In this study, we unveil a novel role for THUMPD3 in lung cancer cells. Depletion of the enzyme from lung cancer cells significantly impairs their fitness, negatively impacting key cellular processes such as proliferation and migration. Notably, exogenous expression of THUMPD3 in normal lung fibroblasts stimulates their proliferation rate. Additionally, transcriptome-wide analyses reveal that depletion of THUMPD3 from lung cancer cells induces substantial changes in the expression of cell surface proteins, including those comprising the extracellular matrix (ECM). We further demonstrate that THUMPD3 maintains expression of an extra-domain B (EDB) containing pro-tumour isoform of Fibronectin-1 mRNA, encoding FN1, an important ECM protein. Crucially, depletion of THUMPD3 promotes an alternative splicing event that removes the EDB- encoding exon from Fibronectin-1. This is consistent with THUMPD3 depletion reducing cellular proliferation and migration. Moreover, depletion of THUMPD3 selectively and preferentially affects the alternative splicing of ECM and cell adhesion molecule encoding transcripts, as well as those encoding neurodevelopmental proteins. Overall, these findings highlight THUMPD3 as an important player in regulating cancer-relevant alternative splicing and they provide a rationale for further investigations into THUMPD3 as a candidate target in anti-cancer therapy.
-
32- Mahdavi-Amiri, Y.; Hu, M. S. J.; Frias, N.; Movahedi, M.; Csakai, A.; Marcaurelle, L. A.; Hili, R. "Photoredox-catalysed Hydroaminoalkylation of on-DNA N-Arylamines" Org. Biomol. Chem. 2023, 21, 1463–1467.
+An efficient approach to the photoredox-catalysed hydroaminoalkylation between on-DNA secondary N-substituted (hetero)arylamines and vinylarenes has been developed and explored. The methodology was examined with a broad scope of vinylarenes and secondary arylamines to establish a preferred building block profile for the process. Compatible substrates furnished the desired derivitised amine products in modest to excellent conversions and with minimial or no detectable by-products.
>Original preprint of this manuscript is available at ChemRxiv

-
31- Chung Kim Chung, K.; Mahdavi-Amiri, Y.; Korfmann, C.; Hili, R. "PhOxi-Seq: Single-nucleotide resolution sequencing of N2-methylation at guanosine in RNA by photoredox catalysis" J. Am. Chem. Soc. 2022, 144, 5723–5727.
+Chemical modifications regulate the fate and function of cellular RNAs. Newly developed sequencing methods have allowed a deeper understanding of the biological role of RNA modifications; however, the vast majority of post-transcriptional modifications lack a well-defined sequencing method. Here, we report a photo-oxidative sequencing (PhOxi-seq) approach for guanosine N2-methylation — a common methylation mark seen in N2-methylguanosine (m2G) and N2,N2-dimethylguanosine (m22G). Using visible light-mediated organic photoredox catalysis, m2G and m22G are chemoselectively oxidized in the presence of canonical RNA nucleosides, which results in a strong mutation signature observed during sequencing. PhOxi-seq was demonstrated on various tRNAs and rRNA to reveal N2-methylation with excellent response and markedly improved read-through at m22G sites.
>Original preprint of this manuscript is available at ChemRxiv

-
30- Movahedi, M; Khamissi, N.; Hili, R. "Ligase-Catalyzed Oligonucleotide Polymerization (LOOPER): Evolution of chemically diverse aptamer libraries" Aptamers 2021, 5, 22–30.
+Expanding the chemical diversity of oligonucleotide libraries has allowed the evolution of synthetic nucleic acid polymers with enhanced molecular recognition and catalysis. Thus, methods that enable the sequence-defined incorporation of diverse chemical modifications are of particular importance in developing novel or improved nucleic acid polymers for diagnostics and therapeutics. In this review, we discuss the development of ligase-catalyzed oligonucleotide polymerization (LOOPER) as a method to increase the chemical diversity of oligonucleotide libraries, and its application towards the evolution of modified aptamers. An evaluation on the use of different ligases, scope and number of modifications, sequence space, and evolutionary outcomes from in vitro selections is provided, along with a critical lens on challenges to be addressed for the method to mature into a more widely adapted technology.

-
29- Le, A.; Krylova, S.; Beloborodov, S.; Wang, T.; Hili, R.; Johnson, P.; Li, F.; Veedu, R.; Krylov, S. "How to Develop and Prove High-Efficiency Selection of Ligands from Oligonucleotide Libraries: A Universal Framework for Aptamers and DNA-Encoded Small-Molecule Ligands" Anal. Chem. 2021, 93, 5343–5354.
+Screening molecular libraries for ligands capable of binding proteins is widely used for hit identification in the early drug discovery process. Oligonucleotide libraries provide a very high diversity of compounds, while the combination of the polymerase chain reaction and DNA sequencing allow the identification of ligands in low copy numbers selected from such libraries. Ligand selection from oligonucleotide libraries requires mixing the library with the target followed by the physical separation of the ligand–target complexes from the unbound library. Cumulatively, the low abundance of ligands in the library and the low efficiency of available separation methods necessitate multiple consecutive rounds of partitioning. Multiple rounds of inefficient partitioning make the selection process ineffective and prone to failures. There are continuing efforts to develop a separation method capable of reliably generating a pure pool of ligands in a single round of partitioning; however, none of the proposed methods for single-round selection have been universally adopted. Our analysis revealed that the developers’ efforts are disconnected from each other and hindered by the lack of quantitative criteria of selection quality assessment. Here, we present a formalism that describes single-round selection mathematically and provides parameters for quantitative characterization of selection quality. We use this formalism to define a universal strategy for development and validation of single-round selection methods. Finally, we analyze the existing partitioning methods, the published single-round selection reports, and some pertinent practical considerations through the prism of this formalism. This formalism is not an experimental protocol but a framework for correct development of experimental protocols. While single-round selection is not a goal by itself and may not always suffice selection of good-quality ligands, our work will help developers of highly efficient selection approaches to consolidate their efforts under an umbrella of universal quantitative criteria of method development and assessment.

-
28- Mahdavi-Amiri, Y.; Chung Kim Chung, K.; Hili, R. "Single-Nucleotide Resolution of N6 -Adenine Methylation Sites in DNA and RNA by Nitrite Sequencing" Chem. Sci. 2021, 12, 606–612. (part of the 2020 Chemical Science HOT Article Collection)
+A single-nucleotide resolution sequencing method of N6-Adenine methylation sites in DNA and RNA is described. Using sodium nitrite under acidic conditions, chemoselective deamination of unmethylated adenines readily occurs, without competing deamination of N6-Adenine sites. The deamination of adenines results in the formation of hypoxanthine bases, which are read by polymerases and reverse transcriptases as guanine; the methylated adenine sites resist deamination and are read as adenine. The approach, when coupled with high-throughput DNA sequencing and mutational analysis, enables the identification of N6-Adenine sites in RNA and DNA within various sequence contexts.

-
27- Kong, D.; Movahedi, M.; Mahdavi-Amiri, Y.; Yeung, W.; Tiburcio, T R.; Chen, D.; Hili, R. "Evolutionary Outcomes of Diversely-Functionalized Aptamers Isolated from In Vitro Evolution" ACS Synth. Biol. 2020, 9, 1, 43–52.
+Expanding the chemical diversity of aptamers remains an important thrust in the field in order to increase their func-tional potential. Previously, our group developed LOOPER, which enables the incorporation of up to 16 unique modi-fication through-out a ssDNA sequence, and applied it to the in vitro evolution of thrombin binders. As LOOPER-derived highly-modified nucleic acids polymers are governed by two interrelated evolutionary variables, namely functional modifications and sequence, the evolution of this polymer contrasts with that of canonical DNA. Herein we provide in-depth analysis of the evolution, including structure-activity relationships, mapping of evolutionary pres-sures on the library, and analysis of plausible evolutionary pathways that resulted in the first LOOPER-derived ap-tamer, TBL1. A detailed picture of how TBL1 interacts with thrombin and how it may mimic known peptide binders of thrombin is also proposed. Structural modelling and folding studies afford insights into how the aptamer displays critical modifications and also how modification enhance the structural stability of the aptamer. A discussion of bene-fits and potential limitations of LOOPER during in vitro evolution is provided, which will serve to guide future evolu-tions of this highly-modified class of aptamers.[READ ARTICLE]
-
26- Guo, C.; Mahdavi-Amiri, Y.; Hili, R. "Influence of Linker Length on Ligase-Catalyzed Oligonucleotide Polymerization" ChemBioChem, 2019, 20, 793–799. (ChemBioTalents issue)(Cover issue)
+Ligase‐catalyzed oligonucleotide polymerization (LOOPER) that enables the sequence‐defined generation of DNA with up to 16 different modifications has recently been developed. This approach was used to develop new classes of diversely modified DNA aptamers for molecular recognition through in vitro evolution. The modifications in LOOPER are appended by use of a long hexane‐1,6‐diamine linker, which could negatively impact binding thermodynamics. Here we explore the incorporation of modifications with the aid of shorter linkers and the use of commercially available phosphoramidites and assess their efficiency and fidelity of incorporation. We observed that shorter linkers are less tolerated during LOOPER, with very short linkers providing high levels of error and sequence bias. An ethane‐1,2‐diamine linker was found to be optimal in terms of yield, efficiency, and bias; however, codon adjustment was necessary. This shorter‐linker anticodon set for LOOPER should prove valuable in exploring the impact of diverse chemical modifications on the molecular function of DNA. [READ ARTICLE] [CHECK OUT COVER]

-
25- Lei, Y.; Washington, J.; Hili, R. "Efficiency and fidelity of T3 DNA ligase in ligase-catalysed oligonucleotide polymerisations" Org. Biomol. Chem., 2019, 17, 1962–1965. (New Talent issue)
+Ligase-catalyzed oligonucleotide polymerisations (LOOPER) can readily generate libraries of diversely-modified nucleic acid polymers, which can be subjected to iterative rounds of in vitro selection to evolve functional activity. While there exists several different DNA ligases, T4 DNA ligase has most often been used for the process. Recently, T3 DNA ligase was shown to be effective in LOOPER; however, little is known about the fidelity and efficiency of this enzyme in LOOPER. In this paper we evaluate the efficiency of T3 DNA ligase and T4 DNA ligase for various codon lengths and compositions within the context of polymerisation fidelity and yield. We find that T3 DNA ligase exhibits high effiiciency and fidelity with short codon lengths, but struggles with longer and more complex codon libraries, while T4 DNA ligase exhibits the oppositve trend. Interestingly, T3 DNA ligase is unable to accommodate modifications at the 8-position of adenosine when integrated into short codons, which will create challenges in expanding the available codon set for the process. The limitations and strengths of the two ligases are further discussed within the context of LOOPER. [READ ARTICLE]

-
24- Kochmann, S.; Le, A. T. H; Hili, R.; Krylov, S. N "Predicting Efficiency of NECEEM-Based Selection of Protein Binders from DNA-Encoded Libraries" Electrophoresis, 2018, 39, 2991–2996.
+Nonequilibrium capillary electrophoresis of equilibrium mixtures (NECEEM) is an affinity method for separating binder-target complexes from nonbinders by gel-free CE. NECEEM is a promising high-efficiency method for partitioning protein binders from nonbinders in DNA-encoded libraries (DEL), such binders are used as "hits" in drug development. It is important to be able to predict the efficiency of NECEEM-based partitioning, which is the efficiency of collecting binders while removing nonbinders for a specific protein and a specific DEL with a minimum of empirical information. Here, we derive and study the dependence of efficiency of NECEEM-based partitioning on electrophoretic mobilities of the protein and the DNA moiety in DEL compounds. Our derivation is based upon a previously found relation between the electrophoretic mobility of protein-binder complex and measured electrophoretic mobilities of the protein and unbound DEL and their estimated sizes. The derivation utilizes the assumption of Gaussian shapes of electrophoretic peaks and the approximation of the efficiency of partitioning by the background of nonbinders - a fraction of nonbinders, which elutes along with protein-binder complexes. Our results will serve as a guiding tool for planning the NECEEM-based partitioning of protein binders from non-binders in DELs. In particular, it can be used to estimate a minimum number of rounds of partitioning required for the desired level of DEL enrichment. [READ ARTICLE]
-
23- Guo, C.; Kong, D.; Lei, Y.; Hili, R. "Expanding the Chemistry of DNA" Synlett 2018, 29, 1405–1414 (Invited SYNPACTS review and Cover Issue).
+Nucleic acid polymers can be evolved to exhibit desired properties, including molecular recognition of a molecular target and catalysis of a specific reaction. These properties can be readily evolved despite the dearth of chemical diversity available to nucleic acid polymers, especially when compared to the rich chemical complexity of proteins. Expansion of nucleic acid chemical diversity has therefore been an important thrust for improving their properties for analytical and biomedical applications. Herein, we briefly describe the current state-of-the-art for the sequence-defined incorporation of modifications throughout an evolvable nucleic acid polymer. This includes contributions from our own lab, which have expanded the chemical diversity of nucleic acid polymers closer to the level observed in proteinogenic polymers.[READ ARTICLE]

-
22- Kong, D.; Yeung, W.; Hili, R. "In Vitro Selection of Diversely-Functionalized Aptamers" J. Am. Chem. Soc. 2017, 139, 13977–13980.
+We describe the application of T4 DNA ligase-catalyzed DNA templated oligonucleotide polymerization toward the evolution of a diversely functionalized nucleic acid aptamer for human α-thrombin. Using a 256-membered ANNNN co-monomer library comprising 16 sub-libraries modified with different functional groups, a highly-functionalized aptamer for thrombin was raised with a dissociation constant of 1.6 nM. The aptamer was found to be selective for thrombin, and required the modifications for binding affinity. This study demonstrates the most differentially functionalized nucleic acid aptamer discovered by in vitro selection and should enable the future exploration of functional group dependence during the evolution of nucleic acid polymer activity.[READ ARTICLE]

-
21- Hook, K. D.; Chambers, J.; Hili, R. "A Platform for High-Throughput Screening of DNA-Encoded Catalyst Libraries in Organic Solvents" Chem. Sci. 2017, 8, 7072–7076.
+We have developed a novel high-throughput screening platform for the discovery of small-molecules catalysts for bond-forming reactions. The method employs an in vitro selection for bond-formation using amphiphilic DNA-encoded small molecules charged with reaction substrate, which enables selections to be conducted in a variety of organic or aqueous solvents. Using the amine-catalysed aldol reaction as a catalytic model and high-throughput DNA sequencing as a selection read-out, we demonstrate the 1200-fold enrichment of a known aldol catalyst from a library of 16.7-million uncompetitive library members.[READ ARTICLE]

-
20- Lei, Y.; Hili, R. "Structure-Activity Relationships of the ATP cofactor in Ligase-Catalysed Oligonucleotide Polymerisations" Org. Biomol. Chem. 2017, 15, 2349–2352.
+The T4 DNA ligase-catalysed oligonucleotide polymerisation process has been recently developed to enable the incorporation of multiple functional groups throughout a nucleic acid polymer. T4 DNA ligase requires ATP as a cofactor to catalyse phosphodiester bond formation during the polymer process. Herein, we describe the structure-activity relationship of ATP within the context of T4 DNA ligase-catalyzed oligonucleotide polymerisation. Using high-throughput sequencing, we study not only the influence of ATP modification on polymerisation efficiency, but also on the fidelity and sequence bias of the polymerisation process.[READ ARTICLE]

-
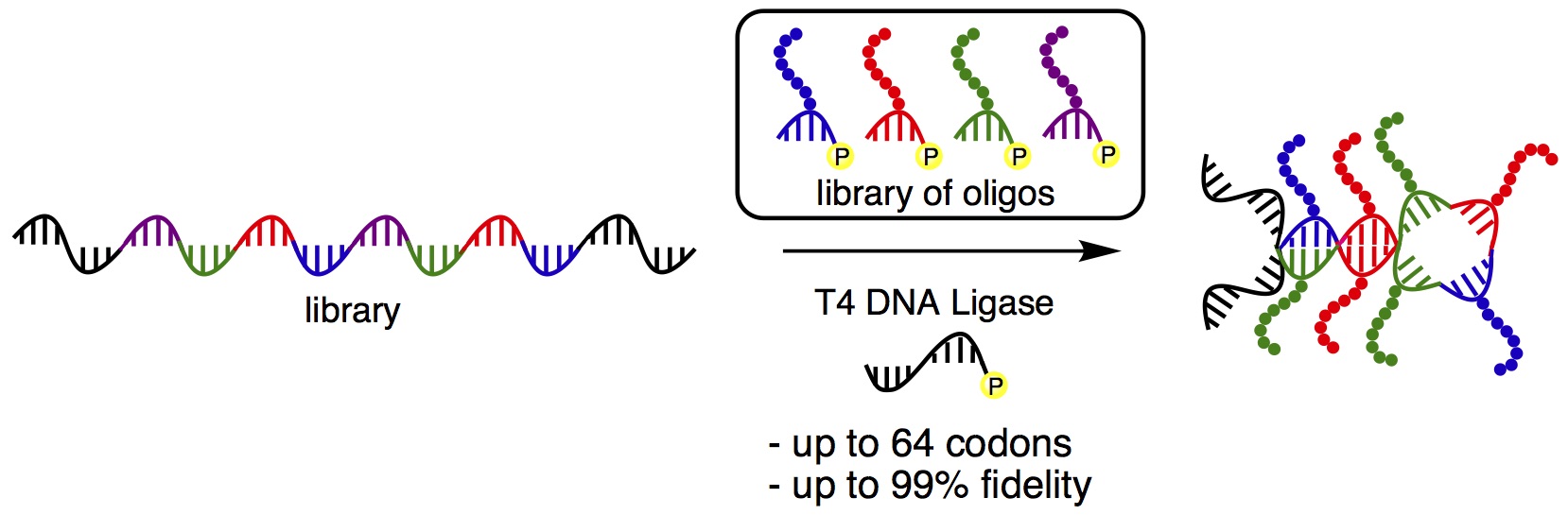
19- Guo, C.; Hili, R. "Fidelity of the DNA Ligase-Catalyzed Scaffolding of Peptide Fragments on Nucleic Acid Polymers" Bioconjugate Chem. 2017, 28, 314–318.
+We describe the development and analysis of the T4 DNA ligase-catalyzed DNA templated polymerization of pentanucleotides modified with peptide fragments toward the generation of ssDNA-scaffolded peptides. A high-throughput duplex DNA sequencing method was developed to facilitate the determination of fidelity for various codons sets and library sizes used during the polymerization process. With this process, we identified several codon sets that enable the efficient and sequence-specific incorporation of peptide fragments along a ssDNA template at fidelities up to 99% and with low sequence bias. These findings mark a significant advance in generating evolvable biomimetic polymers and should find ready application to the in vitro selection of molecular recognition.[READ ARTICLE]
-
18- Kong, D.‡; Lei, Y.‡; Yeung, W.; Hili, R. "Enzymatic Synthesis of Sequence-Defined Synthetic Nucleic Acid Polymers with Diverse Functional Groups" Angew. Chem. Int. Ed. 2016, 55, 13164–13168.
‡ These authors contributed equally
This work was recommended in F1000Prime

+The development and in-depth analysis of T4 DNA ligase-catalyzed DNA templated oligonucleotide polymerization toward the generation of diversely functionalized nucleic acid polymers is described. The NNNNT codon set enables low codon bias, high fidelity, and high efficiency for the polymerization of ANNNN libraries comprising various functional groups. The robustness of the method was highlighted in the copolymerization of a 256-membered ANNNN library comprising 16 sub-libraries modified with different functional groups. This enabled the generation of diversely functionalized synthetic nucleic acid polymer libraries with 93.8 % fidelity. This process should find ready application in DNA nanotechnology, DNA computing, and in vitro evolution of functional nucleic acid polymers.[READ ARTICLE]

-
17- Kong, D.; Yeung, W.; Hili, R. "Generation of Synthetic Copolymer Libraries by Combinatorial Assembly on Nucleic Acid Templates" ACS Comb. Sci. 2016, 18, 355–370. (Invited Review and Cover Issue)
+Recent advances in nucleic acid-templated copolymerization have expanded the scope of sequence-controlled synthetic copolymers beyond the molecular architectures witnessed in nature. This has enabled the power of molecular evolution to be applied to synthetic copolymer libraries in order to evolve molecular function ranging from molecular recognition to catalysis. This review seeks to summarize different approaches available to generate sequence-defined monodispersed synthetic copolymer libraries using nucleic acid-templated polymerization. Key concepts and principles governing nucleic acid-templated polymerization, as well as the fidelity of various copolymerization technologies, will be described. The review will focus on methods that enable the combinatorial generation of copolymer libraries and their molecular evolution for desired function.[READ ARTICLE][CHECK OUT COVER]
-
16- Lei, Y.; Kong, D.; Hili, R. "A High-Fidelity Codon Set for the T4 DNA Ligase-Catalyzed Polymerization of Modified Oligonucleotides" ACS. Comb. Sci. 2015, 17, 716–721.
+In vitro selection of nucleic acid polymers can readily deliver highly specific receptors and catalysts for a variety of applications; however, it is suspected that the functional group deficit of nucleic acids has limited their potential with respect to proteinogenic polymers. This has stimulated research toward expanding their chemical diversity to bridge the functional gap between nucleic acids and proteins in order to develop a superior biopolymer. In this study we investigate the effect of codon library size and composition on the sequence specificity of T4 DNA ligase in the DNA-templated polymerization of both unmodified and modified oligonucleotides. Using high-throughput DNA sequencing of duplex pairs, we have uncovered a 256-membered codon set that yields sequence-defined modified ssDNA polymers in high yield and with high fidelity.[READ ARTICLE]

-
15- Guo, C. Watkins, C. P. Hili, R. "Sequence-Defined Scaffolding of Peptides on Nucleic Acid Polymers" J. Am. Chem. Soc. 2015, 137, 11191–11196
+We have developed a method for the T4 DNA ligase-catalyzed DNA-templated polymerization of 5′-phosphorylated pentanucleotides containing peptide fragments. The polymerization proceeds sequence-specifically to generate DNA-scaffolded peptides in excellent yields. The method has been shown to tolerate peptides ranging from two to eight amino acids in length with a wide variety of functionality. We validated the capabilities of this system in a mock selection for the enrichment of a His-tagged DNA-scaffolded peptide phenotype from a library, which exhibited a 190-fold enrichment after one round of selection. This strategy demonstrates a promising new approach to allowing the generation and in vitro selection of high-affinity reagents based upon single-stranded DNA scaffolding of peptide fragments. [READ ARTICLE]



Research from Toronto and Harvard
-
14- Niu, J.; Hili, R.; Liu, D. R. “Enzyme-Free Translation of DNA into Sequence-Defined Synthetic Polymers Structurally Unrelated to Nucleic Acids” Nature Chemistry, 2013, 5, 282–292.
This work was featured in a News & Views article in Nature Chemistry 5, 252-253 (2013), in a Science and Technology Concentrate in C&E News91 [9], 45 (2013) and in a news story in Chemistry World (March 3, 2013), and in a News & Views article in Nature Biotechnology 31, 613 (2013).
+The translation of DNA sequences into corresponding biopolymers enables the production, function and evolution of the macromolecules of life. In contrast, methods to generate sequence-defined synthetic polymers with similar levels of control have remained elusive. Here, we report the development of a DNA-templated translation system that enables the enzyme-free translation of DNA templates into sequence-defined synthetic polymers that have no necessary structural relationship with nucleic acids. We demonstrate the efficiency, sequence-specificity and generality of this translation system by oligomerizing building blocks including polyethylene glycol, α-(D)-peptides, and β-peptides in a DNA-programmed manner. Sequence-defined synthetic polymers with molecular weights of 26 kDa containing 16 consecutively coupled building blocks and 90 densely functionalized β-amino acid residues were translated from DNA templates using this strategy. We integrated the DNA-templated translation system developed here into a complete cycle of translation, coding sequence replication, template regeneration and re-translation suitable for the iterated in vitro selection of functional sequence-defined synthetic polymers unrelated in structure to nucleic acids. [READ ARTICLE]

-
13- Hili, R.; Niu, J.; Liu, D. R. “DNA Ligase-Mediated Translation of DNA Into Densely Functionalized Nucleic Acid Polymers” J. Am. Chem. Soc, 2013, 135, 98–101.
This work was selected as a JACS Spotlight: J. Am. Chem. Soc., 2013, 135 (5), pp 1627–1628
+We developed a method to translate DNA sequences into densely functionalized nucleic acids by using T4 DNA ligase to mediate the DNA-templated polymerization of 5′-phosphorylated trinucleotides containing a wide variety of appended functional groups. This polymerization proceeds sequence specifically along a DNA template and can generate polymers of at least 50 building blocks (150 nucleotides) in length with remarkable efficiency. The resulting single-stranded highly modified nucleic acid is a suitable template for primer extension using deep vent (exo-) DNA polymerase, thereby enabling the regeneration of template DNA. We integrated these capabilities to perform iterated cycles of in vitro translation, selection, and template regeneration on libraries of modified nucleic acid polymers. [READ ARTICLE]

-
12- Assem, N.; Hili, R.; He, Z.; Kasahara, T.; Inman, B.; Decker, S.; Yudin, A. K. “The Role of Reversible Dimerization in Reactions of Amphoteric Aziridine Aldehydes” J. Org. Chem., 2012, 77, 5613–5623.
+Unprotected aziridine aldehydes belong to the amphoteric class of molecules by virtue of their dual nucleophilicity/electrophilicity. The dimeric nature of these molecules, brought together by a weak and reversible aminal “connection”, was found to be an important element of reactivity control. We present evidence that reversible dimer dissociation is instrumental in aziridine aldehyde transformations. We anticipate further developments that will unveil other synthetic consequences of remote control of selectivity through forging reversible covalent interactions. [READ ARTICLE]

-
11- Rotstein, B. H.; Rai, V.; Hili, R.; Yudin, A. K. “Synthesis of Peptide Macrocycles Using Unprotected Amino Aldehydes” Nature Protocols, 2010, 5, 1813–1822.
+This protocol describes a method for synthesizing peptide macrocycles from linear peptide precursors, isocyanides and aziridine aldehydes. The effects of the reaction components on the efficiency of the process are discussed. Macrocyclization is exemplified by the preparation of a nine-membered ring peptide macrocycle. The product is further functionalized by nucleophilic opening of the aziridine ring with a fluorescent thiol. This transformation constitutes a useful late-stage functionalization of a macrocyclic peptide molecule. The experimental section describes the selection of the required starting materials, and the preparation of a representative aziridine-2-carboxaldehyde dimer. The synthesis and isolation of the peptide macrocycle can be accomplished in 6 h, and the ring-opening requires approximately 6–8 h. The aziridine-2-carboxaldehyde reagent is commercially available or can be synthesized from readily available starting materials in approximately 4 d. The strategy described is not limited to the specific peptide, isocyanide, aziridine aldehyde or nucleophile used in the representative synthesis. [READ ARTICLE]

-
10- Jebrail, M. J.; Ng, A. H. C.; Rai, V.; Hili, R.; Yudin, A. K.; Wheeler, A. “Synchronized Synthesis of Peptide-Based Macrocycles by Digital microfluidics“ Angew. Chem. Int. Ed. 2010, 49, 8625–8629. (Inside Cover issue)
+Digital synthesis has been applied to the formation of peptide-based macrocycles and their analogues with side chains appended during late-stage aziridine ring-opening. Discrete nanoliter- to microliter-sized droplets of samples and reagents are controlled in parallel by applying a series of electrical potentials to an array of electrodes coated with a hydrophobic insulator. [READ ARTICLE] [COVER ART]

-
9- Hili, R.; Rai, V.; Yudin, A. K. “Macrocyclization of Linear Peptides Enabled by Amphoteric Molecules” J. Am. Chem. Soc. 2010, 132, 2889–2891.
This work was highlighted in Science 2010, 327, 1430, and in Chem. Eng. News. 2010, 88, 34. It was also selected for Faculty 1000 Biology
+There has been enormous interest in both naturally occurring and synthetic cyclic peptides as scaffolds that preorganize a given amino acid sequence into a rigid conformation. Such molecules have been employed as nanomaterials, imaging agents, and therapeutics. Unfortunately, the laboratory synthesis of cyclic peptides directly from linear precursors is afflicted by several thermodynamic and kinetic challenges, resulting in low chemical yields and poor chemo- and stereoselectivities. Here we report that amphoteric amino aldehydes can be used for efficient syntheses of cyclic peptides in high yields and selectivities starting from α-amino acids or linear peptides. The cyclizations effectively operate at unusually high molar concentrations (0.2 M), while side processes such as epimerization and cyclodimerization are not observed. The products are equipped with sites that allow for a highly specific, late-stage structural modification. The overall efficiency of the macrocyclization is due to the coexistence of nucleophilic and electrophilic reaction centers in amphoteric amino aldehydes. [READ ARTICLE]

-
8- Hili, R.; Yudin, A. K. “Amphoteric Amino Aldehydes Reroute the Aza-Michael Reaction” J. Am. Chem. Soc., 2009, 131, 16404–16406.
+Amphoteric amino aldehydes, which exist as stable dimers, participate in an aza-Michael/aldol domino reaction with α,β-unsaturated aldehydes to afford stable 1,5-aminohydroxyaldehydes in high yields and diastereoselectivies. The reaction outcome hinges upon the dimeric nature of amphoteric amino aldehydes and the orthogonality between the NH aziridine and the two aldehyde functionalities during the reaction. Through the use of reaction conditions that disfavor dimer dissociation, the aza-Michael process has been directed toward a novel 8-(enolendo)-exo-trig cyclization. The results described herein further demonstrate the potential of amphoteric molecules in reaction discovery. [READ ARTICLE]

-
7- Baktharaman, S.; Hili, R.; Yudin, A. K. “Amino Carbonyl Compounds in Organic Synthesis’’ Aldrichimica Acta, 2008, 41, 109—119. +
Amino aldehydes and amino ketones are versatile building blocks that are indispensable in the synthesis of natural products and pharmaceuticals. Their utility stems from the broad scope of synthetic transformations available to both the amino and carbonyl functional groups. However, the utility of amino aldehydes and ketones is not without shortcomings, as nitrogen- or carbon-protecting groups are usually needed in order to prevent undesired inter- and intramolecular selfcondensation reactions. While serving to prevent these undesired processes, nitrogen protection can also have a detrimental effect on subsequent transformations of the carbonyl group. This review focuses on recent advances in the field of amino carbonyl chemistry.
[READ ARTICLE] -
6- Hili, R.; Baktharaman, S.; Yudin, A. K. “Synthesis of Chiral Amines Using α-amino aldehydes” Eur. J. Org. Chem. 2008, 31, 5201—5213. (Cover Issue)
+If one were to rank chemical reagents on the basis of their “synthetic content”, loosely defined as the density of functional groups per arbitrary unit of molecular space, the α-amino aldehydes will find themselves close to the very top of that list. The presence of synthetically ubiquitous amine and aldehyde functionalities predisposes α-amino aldehydes towards highly convergent bond-forming operations. Such juxtaposition does not come without a price: incompatibility of these functional groups calls for protecting groups. We discuss challenges and recently identified opportunities in this field. [READ ARTICLE] [COVER ART]
-
5- Hili, R.; Yudin, A. K. “Amphoteric Amino Aldehydes Enable Rapid Assembly of Unprotected Amino Alcohols” Angew. Chem. Int Ed.2008, 47, 4188—4191.
+The term “amphoteric” is derived from the Greek “amphoteros”, which literally means “both of two”. Amphoteric amino aldehydes are counterintuitive molecules in that they contain both electrophilic and nucleophilic centers. These small but powerful reagents can be used for the streamlined construction of complex amino alcohol scaffolds (see scheme). Their premature self-destruction is prevented on kinetic grounds. [READ ARTICLE]

-
4- Yudin, A. K., Hili, R. “Overcoming the Demons of Protecting Groups with Amphoteric Molecules” Chem. Eur. J. 2007, 13, 6538—6542.
+Synthetic organic chemists have long depended on protecting group manipulations when faced with the challenges of chemoselectivity and functional group incompatibility. Overcoming this dependence will improve the overall efficiency of chemical synthesis. By taking advantage of orthogonally reactive functional groups, amphoteric molecules can afford access not only to more efficient and strategic syntheses but also to the development of novel chemical transformations. [READ ARTICLE]
-
3- Hili, R.; Yudin, A. K. “Readily Available Unprotected Amino Aldehydes” J. Am. Chem. Soc. 2006, 128, 14772—14773.
+We report a new class of bench-stable compounds that contain seemingly incompatible functional groups: an aldehyde and an unprotected secondary amine. The thermodynamic driving force to undergo condensation between these two functionalities is offset by a high barrier imposed on this process by the aziridine ring strain. The resulting amino aldehydes exist as dimers and in the solid state. They are stable to epimerization and contain two orthogonal reaction centers, namely, an amine/aziridine and an aldehyde. Their ability to act as linchpins has been evaluated in complex heterocycle synthesis. For instance, pentacyclic frameworks can be made in one simple operation using N-benzyltryptamine as the reaction partner. Construction of other molecular skeletons with minimal use of protecting group manipulations should be feasible. [READ ARTICLE]

-
2- Hili, R., Yudin, A. K. “Making Carbon-Nitrogen Bonds in Biological and Chemical Synthesis” Nature Chem. Biol. 2006, 2, 284—287.
+The function of many biologically active molecules requires the presence of carbon-nitrogen bonds in strategic positions. The biosynthetic pathways leading to such bonds can be bypassed through chemical synthesis to synthesize natural products more efficiently and also to generate the molecular diversity unavailable in nature. [READ ARTICLE]
-
1- Krasnova, L.B.; Hili, R.; Chernoloz, O.V.; Yudin, A.K. “Phenyliodine(III) Diacetate as a Mild Oxidant for Aziridination of Olefins and Imination of Sulfoxides with N-aminophthalimide” Arkivoc 2005, 4, 26—38.
+Phenyliodine(III) diacetate (PIDA) was found to promote facile nitrene transfer to olefins and sulfoxides giving aziridines and sulfoximines, respectively, in high isolated yields and with high selectivities. The reactions are tolerant for a range of functional groups and proceed under mild conditions. The feasibility of scale-up has been demonstrated. [READ ARTICLE]